At DevLearn next week, I’ll be talking about content systems in session 109. The point is that instead of monolithic content, we want to start getting more granular for more flexible delivery. And while there I’ll be talking about some of the options on how, here I want to make the case about why, in a simplified way.
As an experiment (gotta keep pushing the envelope in a myriad of ways), I’ve created a video, and I want to see if I can embed it. Fingers crossed. Your feedback welcome, as always.

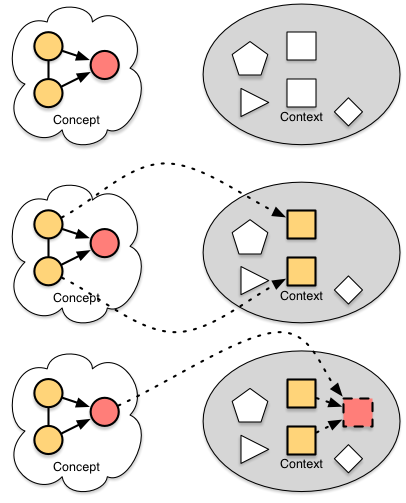 The process is to identify the elements, and the relationships, and then additional dimensions. Then you represent each, place them (elements first, relationships second, dimensions last), and tune.
The process is to identify the elements, and the relationships, and then additional dimensions. Then you represent each, place them (elements first, relationships second, dimensions last), and tune.