For the current ADL webinar series on mobile, I gave a presentation on contextualizing mobile in the larger picture of L&D (a natural extension of my most recent books). And a question came up about whether I thought wearables constituted mobile. Naturally my answer was yes, but I realized there’s a larger issue, one that gets meta as well as mobile.
So, I’ve argued that we should be looking at models for guiding our behavior. That we should be creating them by abstracting from successful practices, we should be conceptualizing them, or adopting them from other areas. A good model, with rich conceptual relationships, provides a basis for explaining what has happened, and predicting what will happen, giving us a basis for making decisions. Which means they need to be as context-independent as possible.
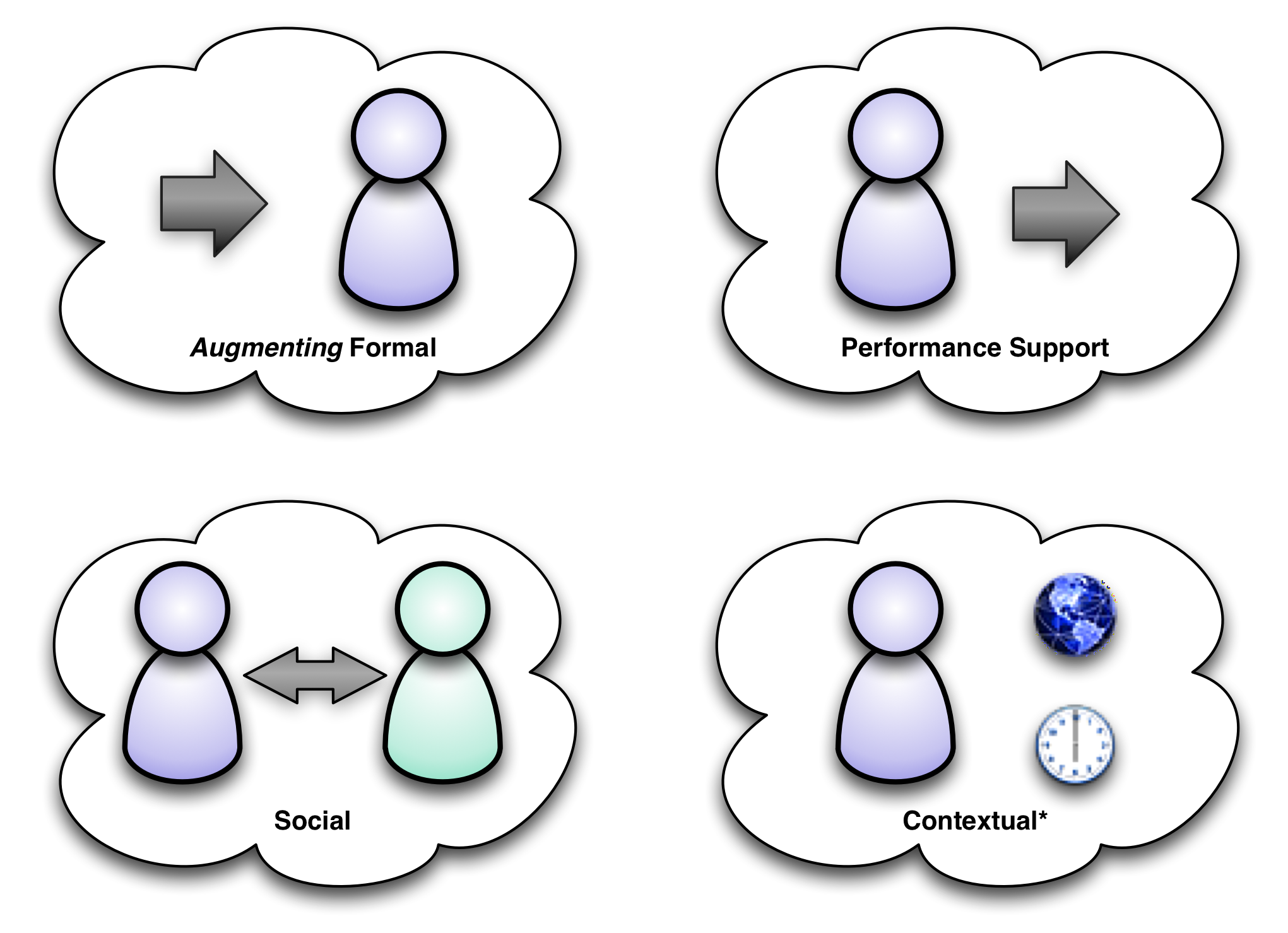 So, for instance, when I developed the mobile models I use, e.g. the 4C‘s and the applications of learning (see figure), I deliberately tried to create an understanding that would transcend the rapid changes that are characterizing mobile, and make them appropriately recontextualizable.
So, for instance, when I developed the mobile models I use, e.g. the 4C‘s and the applications of learning (see figure), I deliberately tried to create an understanding that would transcend the rapid changes that are characterizing mobile, and make them appropriately recontextualizable.
In the case of mobile, one of the unique opportunities is contextualization. That means using information about where you are, when you are, which way you’re looking, temperature or barometric pressure, or even your own state: blood pressure, blood sugar, galvanic skin response, or whatever else skin sensors can detect.
To put that into context (see what I did there): with desktop learning, augmenting formal could be emails that provide new examples or practice that spread out over time. With a smartphone you can do the same, but you could also have a localized information so that because of where you were you might get information related to a learning goal. With a wearable, you might get some information because of what you’re looking at (e.g. a translation or a connection to something else you know), or due to your state (too anxious, stop and wait ’til you calm down).
Similarly for performance support: with a smartphone you could take what comes through the camera and add it onto what shows on the screen; with glasses you could lay it on the visual field. With a watch or a ring, you might have an audio narration. And we’ve already seen how the accelerometers in fit bracelets can track your activity and put it in context for you.
Social can not only connect you to who you need to know, regardless of device or channel, but also signal you that someone’s near, detecting their face or voice, and clue you in that you’ve met this person before. Or find someone that you should meet because you’re nearby.
All of the above are using contextual information to augment the other tasks you’re doing. The point is that you map the technology to the need, and infer the possibilities. Models are a better basis for elearning, too so that you teach transferable understandings (made concrete in practice) rather than specifics that can get outdated. This is one of the elements we placed in the Serious eLearning Manifesto, of course. They’re also useful for coaching & mentoring as well, as for problem-solving, innovating, and more.
Models are powerful tools for thinking, and good ones will support the broadest possible uses. And that’s why I collect them, think in terms of them, create them, and most importantly, use them in my work. I encourage you to ensure that you’re using models appropriately to guide you to new opportunities, solutions, and success.
Leave a Reply