At DevLearn next week, I’ll be talking about content systems in session 109. The point is that instead of monolithic content, we want to start getting more granular for more flexible delivery. And while there I’ll be talking about some of the options on how, here I want to make the case about why, in a simplified way.
As an experiment (gotta keep pushing the envelope in a myriad of ways), I’ve created a video, and I want to see if I can embed it. Fingers crossed. Your feedback welcome, as always.
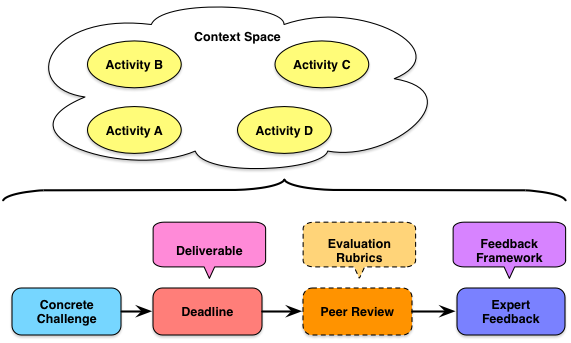 The empirical data is that we learn better when our learning practice is contextualized. And if we want transfer, we should have practice in a spread of contexts that will facilitate abstraction and application to all appropriate settings, not just the ones seen in the learning experience. If the space between our learning applications is too narrow, so too will our transfer be. So our
The empirical data is that we learn better when our learning practice is contextualized. And if we want transfer, we should have practice in a spread of contexts that will facilitate abstraction and application to all appropriate settings, not just the ones seen in the learning experience. If the space between our learning applications is too narrow, so too will our transfer be. So our