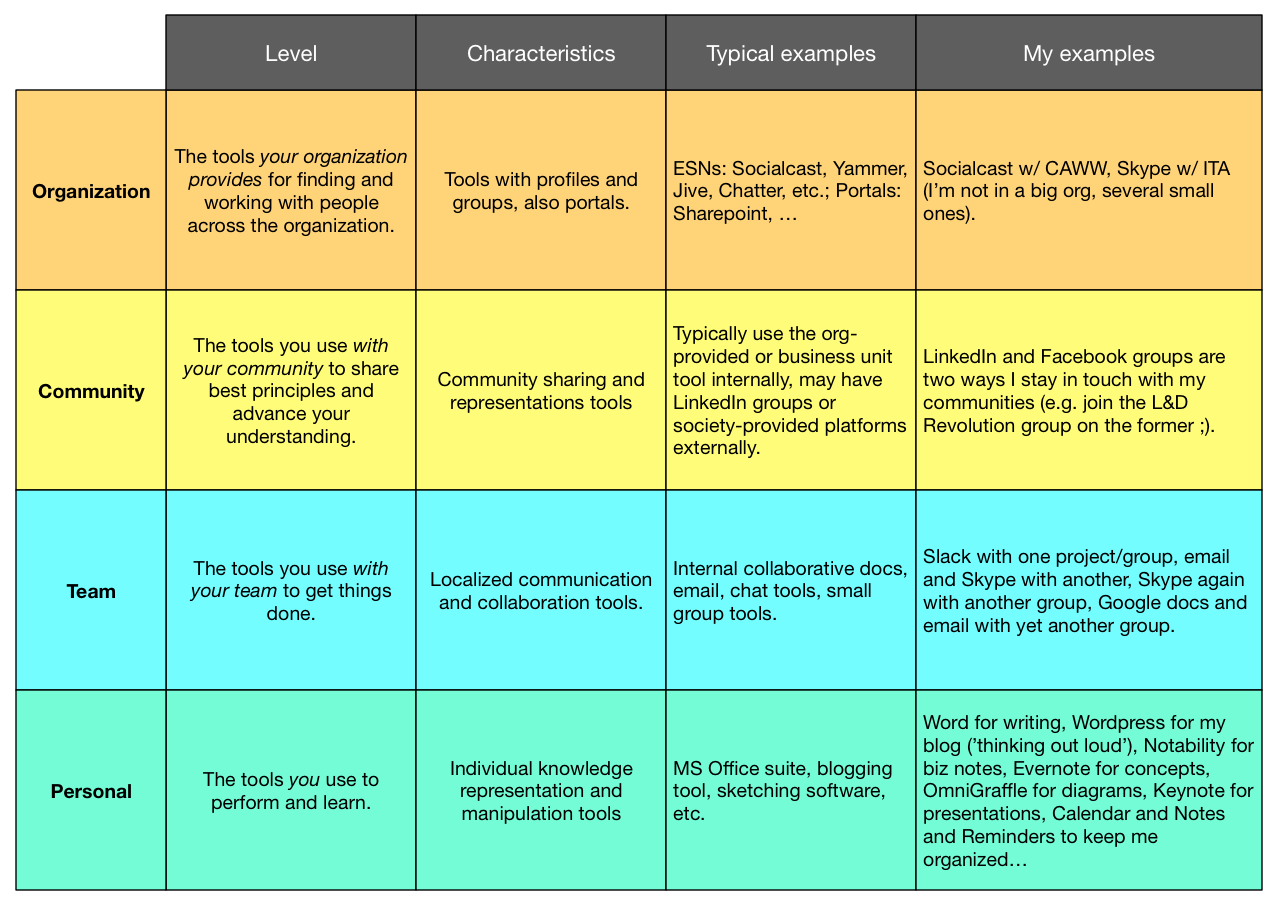
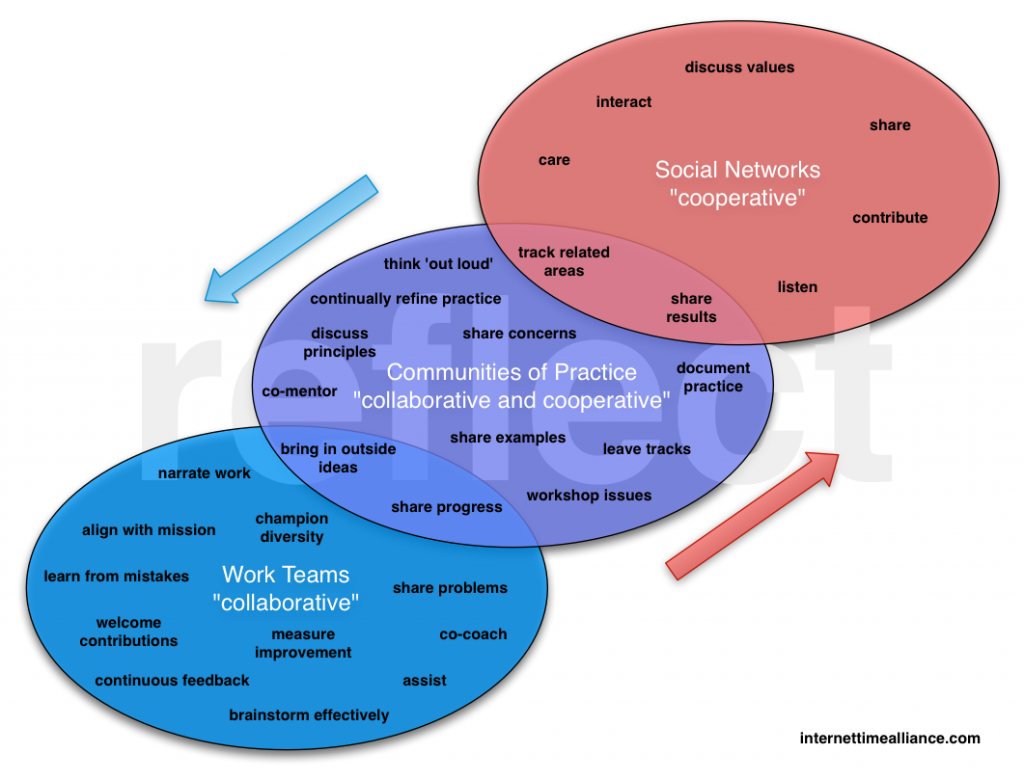
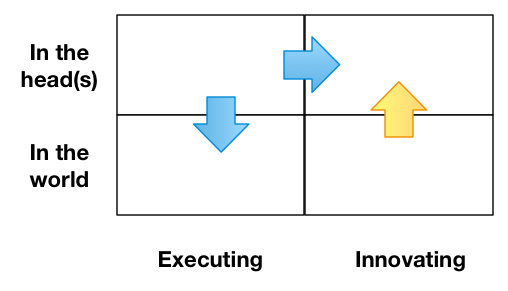
So I was talking with a colleague, who pointed out that my site wasn’t as optimized for finding as it could be, and he recommended a solution. Which led to an ongoing series of activities that have some learnings both at the technical and learning side. So I thought I’d share my learnings about sites.
This being a WordPress site, I use plugins, and my colleague pointed me to a plugin that would guide me through steps to improve my site. And so I installed it. And it led me through several steps. One being improving some elements about each post. And some of these had some ramifications. The steps included:
- adding a focus word or phrase
- adding a meta-description
- post recommendations for including focus word in the first paragraph
- adding images
- and more
I reckon these are good things to be consistent, but while I sometimes include diagrams, I haven’t been rabid about including images. Which I will probably do more, but not ubiquitously (e.g. this post ;). The other things I’ll work on. BTW, I am also getting advice on readability, but I’m less likely to change. This is my blog, after all!
One other change was to move from posts by number (e.g. ?p=#), to having a meaningful title. Which is all well and good, but it conflicted with another situation. See, one of the other recommendations was to be more closely tied to Google’s tools for tracking sites, specifically Search Console. Which had other ramifications.
So, I’ve put Google tracking code into all of my sites, but the code on Learnlets was old. I’d put it in, and then my ISP changed the settings on my blog so I couldn’t use the built-in editor to edit the header and footer of the site pages (for security). Which meant I had to find the old code and replace it with FTP. Except, in all the myriad files in a WordPress site, I had no idea where.
Now, I’d try to do this once I’d gotten all my sites tied into Google Analytics, including searching the WP file folders, and browsing a number, to no avail. And I’d searched for guidance, similarly to no avail. I tried again this time, still to no avail. I even found a recommended plugin that would allow you to add code into the header, but it didn’t work.
Specifically, even though my site was registering in Google Analytics, it wasn’t validated with the Search Console. I tried a number of their recommended steps, like adding a generated .html file into the site and putting a special txt message in my DNS record via my domain name host. (And if you don’t know what this means, it’s not really essential except to note that it’s clearly at the very edge of my deteriorating tech skills. ;)
I finally got on the phone to my ISP, and he gave me the clue I needed to find the right file with the header. Then I could download the file, edit it, and re upload it. Which is always nervous to me: changing a core and ubiquitous file for your site that could totally stuff things up!
Well, long story short, it worked. I’m now registered with the Search Console, with current Analytics code. Though, in the process of changing my url style for my blog, it is now generating 404 errors on pages that use the old mechanism (it seemed to work okay on some newer ones, but apparently is falling apart on some older ones). It’s always something.
So, the important thing: tech stuff ends up being complicated, but what helps are the same innovation (aka informal learning) steps as always. Persistence, a willingness to experiment, a suite of approaches, and a network to fall back on. And also, if you’re using one of my old URLs, it may be a problem to track down! This may well be a problem in my own referring sites (e.g. the Quinnovation News page). Two steps forward, one step back. Here’s to change!