I’ve been working on moving a team to deeper learning design. The goal is to practice what I preach, and make sure that the learning design is competency-aligned, activity-based, and model-driven. Yet, doing it in a pragmatic way.
And this hasn’t been without it’s challenges. I presented to the team my vision, we worked out a process, and started coaching the team during development. In retrospect, this wasn’t proactive enough. There were a few other hiccups.
We’re currently engaged in a much tighter cycle of development and revision, and now feel we’re getting close to the level of effectiveness and engagement we need. Whether a) it’s really better, and b) whether we can replicate it yet scale it as well is an open question.
At core are a few elements. For one, a rabid focus on what learners are doing is key. What do they need to be able to do, and what contexts do they need to do it in?
The competency-alignment focus is on the key tasks that they have to do in the workplace, and making sure we’re preparing them across pre-class, in-class, and post-class activities to develop that ability. A key focus is having them make the decision in the learning experience that they’ll have to make afterward.
I’m also pushing very hard on making sure that there are models behind the decisions. I’m trying hard to avoid arbitrary categorizations, and find the principles that drove those categorizations.
Note that all this is not easy. Getting the models is hard when the resources provided don’t include that information. Avoiding presenting just knowledge and definitions is hard work. The tools we use make certain interactions easy, and other ones not so easy. We have to map meaningful decisions into what the tools support. We end up making tradeoffs, as do we all. It’s good, but not as good as it could be. We’ll get better, but we do want to run in a practical fashion as well.
There are more elements to weave in: layering on some general biz skills is embryonic. Our use of examples needs to get more systematic. As does our alignment of learning goal to practice activity. And we’re struggling to have a slightly less didactic and earnest tone; I haven’t worked hard enough on pushing a bit of humor in, tho’ we are ramping up some exaggeration. There’s only so much you can focus on at one time.
We’ll be running some student tests next week before presenting to the founder. Feeling mildly confident that we’ve gotten a decent take on quality learning design with suitable production value, but there is the barrier that the nuances of learning design are subtle. Fingers crossed.
I still believe that, with practice, this becomes habit and easier. We’ll see.
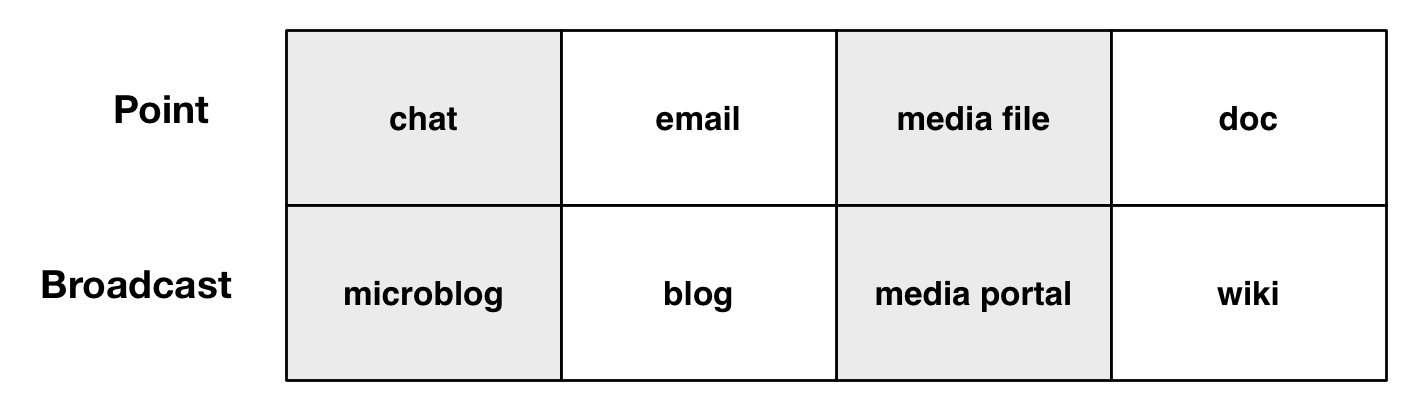
 So, my starting point was realizing that it wasn’t just content. That is, there’s a difference between compute and content where the interactivity was an important part of the 4C’s, so that the characteristics in the content box weren’t discriminated enough. So the new two initial sections are mlearning content and mlearning compute, by self or social. So, we can be getting things for an individual, or it can be something that’s socially generated or socially enabled.
So, my starting point was realizing that it wasn’t just content. That is, there’s a difference between compute and content where the interactivity was an important part of the 4C’s, so that the characteristics in the content box weren’t discriminated enough. So the new two initial sections are mlearning content and mlearning compute, by self or social. So, we can be getting things for an individual, or it can be something that’s socially generated or socially enabled. The point is that content is prepared media, whether text, audio, or video. It can be delivered or accessed as needed. Compute, interactive capability, is harder, but potentially more valuable. Here, an individual might actively practice, have mixed initiative dialogs, or even work with others or tools to develop an outcome or update some existing shared resources.
The point is that content is prepared media, whether text, audio, or video. It can be delivered or accessed as needed. Compute, interactive capability, is harder, but potentially more valuable. Here, an individual might actively practice, have mixed initiative dialogs, or even work with others or tools to develop an outcome or update some existing shared resources.