As I’ve mentioned, I’m working with a startup looking at extending training through small LIFTs. The problem is that most training is ‘event’ based, where learning is in a concentrated time. Which is fine for performing right after. However, much of what we train for are things that may or may not happen soon. What we want is to go from the knowledge after the event to actually performing in new ways after the event, possibly a long time. We need retention from the learning to the situation, and transfer to all appropriate (and no inappropriate) situations. Thus, we need to think differently. And, as I suggested, we’re looking at supporting people not just with formal learning, but beyond, to developing their ability over time. We really want to be transforming from knowledge to performance. So, what’s that look like?
As usual, when I’m supposed to be sleeping is one of the times I end up noodling things over. And, so it was some nights ago. I was thinking about (as I’m wont to do) the cognitive roles that we need. I talk about practice, and models, and examples, and more recently, generative activities. But that’s formal learning, and we have a good evidence base for that. But what about going forward? What sorts of activities make sense?
Here I’m going out of my comfort zone. Yes, I’ve been doing some reading about coaching, particularly domain-independent vs domain-specific coaching. Now, here I don’t necessarily know what the research says specifically, but I do see the convergence of a variety of different models. So, I can make inferences. And post them here to get corrected!
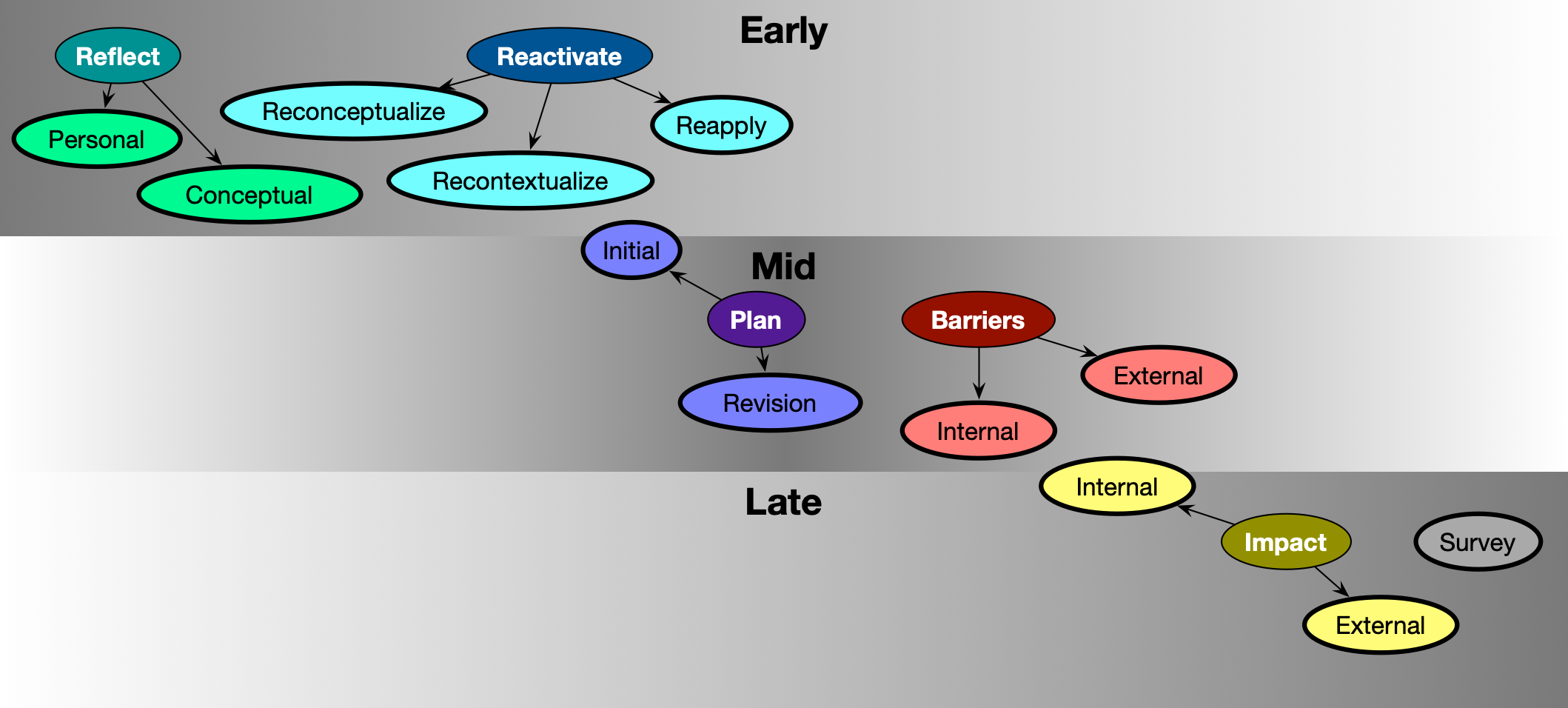 As you might expect, I made a diagram to help me understand. So, I reckon there’s an early, mid, and late stage of development of capability. Formal learning should really be about getting you ready to apply.
As you might expect, I made a diagram to help me understand. So, I reckon there’s an early, mid, and late stage of development of capability. Formal learning should really be about getting you ready to apply.
That is the early phase which includes reflection (really, a generative activity), which can be personal (ala scripts) or conceptual (schemas). Also, reactivation. That is, seeing different ways of looking at it (new models), more examples in context, and of course more practice. (Retrieval practice, of course, where you’re applying the knowledge.)
Then, in mid-phase, your learners are applying, but to real situations, not simulations. Their initial plan on how to apply the knowledge might be part of the end of the early stage, but then it’s time to apply. Which could (should?) lead to revisions of the plan, and on reflecting on any barriers. Those barriers could be internal (their own understanding or hangups), or external (lack of resources, situations, tools, etc). The former are grounds for discussion, the latter for action on the part of the org!
Then, at the late stage, learners should be looking at the impact. They can reflect on the impact on them, which could also be a mid-phase action, but ultimately you want to see if they’re having an impact overall. Then, of course, you could want to survey about the learning experience itself. While it’s all data, the org impact is useful data to evaluate what’s going on and how it’s going, and the survey can help you continue to improve either this or your next initiative.
Those’re my initial thoughts on transforming from knowledge to performance. There’s some overlap, no doubt, e.g. you could continue sending reapplications if there aren’t frequent opportunities in the real world. Likewise, your learners should be assessing impact in the need to revise a plan. Still, this seems to make sense in the first instance, at least to me. (Addressing the ‘when’, how much and what spacing, is what I’ll be talking about at DevLearn. ;) Now, it’s over to you. What have I got wrong, am missing, …?