Ok, so it’s been a wee bit too much about me (my books, themes), yet it occurs to me that I should document what I’m doing. (Which I’ve done before, but this is looking forward, too.) Not just for me (though it helps ;), but it’s because I realized my thinking other than books is actually getting spread out in various places. So, here’s what I’m up to…
Mostly, it’s centering around applying the cognitive and learning sciences to the design of solutions. In a variety of ways, of course. I’ve been working with Upside Learning, serving as their Chief Learning Strategist. They want to do more than pay lip service to learning science (which I laud). I’m working with them on evangelism, internal development, and more. I’m also working with Elevator 9, in this case as advisor. They’re a platform solution to complement live events, again doing so in alignment with our brains. I’m also serving as co-director of the Learning Development Accelerator. That’s a society focused on evidence-informed L&D, and we explore what this approach means in practice. In each, I’ve been advancing my own understanding, and sharing the learnings.
So, at LDA, you can find our podcasts, blog posts (some of which are free to air!), and some programs (some likewise). For members, we’re running some internal programs as well. I’ve been pleased to augment my previous program on You Oughta Know with this year’s YOK Practitioner, where I get to interview some really amazing people. Then there’s also the Think Like A…series, where we talk to representatives of adjacent fields we (should) be plagiarizing. Then there are workshops, and we’re always developing more things.
At Elevator 9, while most of the work is behind the scenes, I did author, and David Grad (the CEO) read and taped, a series of ‘liftologies’. These are short videos talking about the learning science that goes into their offering. When they redo the website, they’ll be easy to find, but right now they’re visible through the E9 LinkedIn page posts.
Upside Learning, on the other hand, has been proactive. They do a podcast with the CEO, Amit Garg (yes, I’ve been on it). They have a blog (and I’ve written some for them). I’ve also done some quick videos on myths. In addition, I’ve written some of their ebooks (topics like impact, microlearning, scenarios). And, of course, some webinars as well. These continue.
All this in conjunction with continuing as Quinnovation! I continue with a few clients, on a limited basis. These, of course, are not public, though the thoughts can percolate out (e.g. in this blog). I’m still doing some events, mostly virtually. For instance, I’ll be talking about the alignment between effective education and engaging events at LXDCon on Tues the 11th (at 7AM PT ). I’ll also be at DevLearn and Learning 2024.
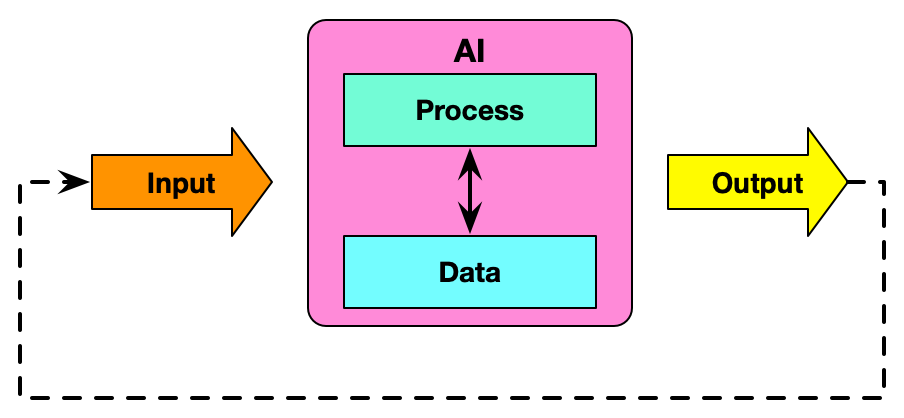
That’s all I can think of at the moment. There’s more in the offing, of course. But for now, that’s what I’m up to. This blog may be (more than) enough, but the other sites prompt different thinking. They’re worth knowing about on their own, too! If you’re interested, these are places to either become evidence-based, apply it, or get it done. Obviously, it’s something I think is important for our industry. (As is knowing the human information processing loop, which I’ve made freely available.) Whatever you do, however you do it, please do avoid the myths and apply the science.